How to Submit Jobs to SLURM#
Some jobs can be time-consuming, and we want to avoid reserving a powerful node for only interaction. So what we can do is have the ‘interactive part’ (Tomwer node) with fewer resources (no GPU, for example) and submit jobs to a node that will be released once the processing is done.
In Tomwer, resource-consuming tasks can be executed on SLURM:
Slice / volume reconstruction
nabu slice
nabu volume
sa-axis
sa-delta-beta
Volume casting
Warning: To launch jobs on SLURM, you need to be on a SLURM client of the ESRF cluster. A simple way to check is to make sure you can access the sbatch command.
Then you will need to handle the job submission and future object by the * SLURM cluster widget * Future supervisor widget
Note: Both are part of the ‘cluster’ group.
SLURM Cluster Widget  #
#
This widget will be used to know the partition and the configuration to create nodes.
You need to add it to the canvas and configure it like
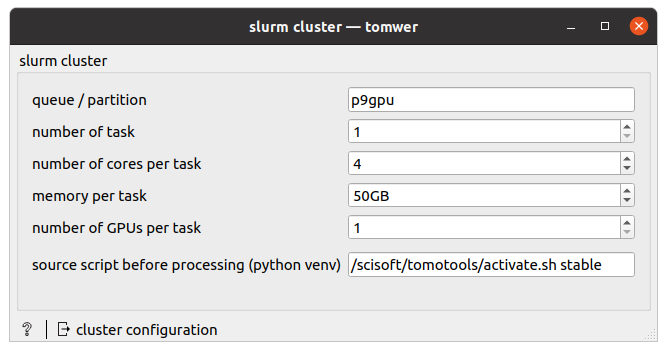
Then you can connect it to one of the widgets handling it (presented above) using the ‘cluster_config’ input. Here we connect it with the nabu volume widget.
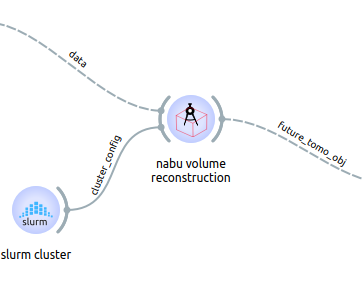
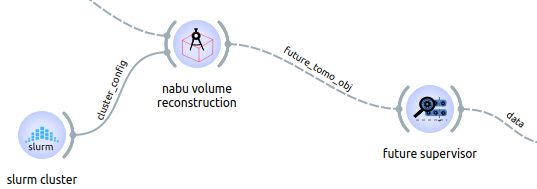
But this time, the widget launching the job to SLURM will return a future tomo obj object. Basically, this is used to wait for the processing to be done.
To wait for the processing to be done and convert it back to a ‘standard’ data or volume object, we need to use the future supervisor widget.
Future Supervisor Widget  #
#
This widget will give feedback on the different jobs currently executed remotely.
Then by default, once a job is finished, you can use it back in your workflow.
Bash Script#
Each process compatible with SLURM will create a bash script (.sh) under the ‘slurm_scripts’ folder.
Log files related to those scripts have the same name but a different extension (.out).
If needed, you can relaunch them from the command line using the sbatch command.
Demo Video of a Submission to SLURM#
Here is a video demonstration of this feature.
Note: The interface of the SLURM cluster has been updated (simplified) since the video, but the behavior/logic behind it is the same.
[1]:
from IPython.display import YouTubeVideo
YouTubeVideo("HYufV7Ya9v8", height=500, width=800)
[1]:
Hands-on - Exercise A#
Reconstruct a slice of the crayon.nx NXtomo (available from /scisoft/tomo_training/part6_edit_nxtomo/) or another dataset if you prefer.
Then reconstruct a few slices of the volume (~20) by submitting the volume reconstruction to the cluster.